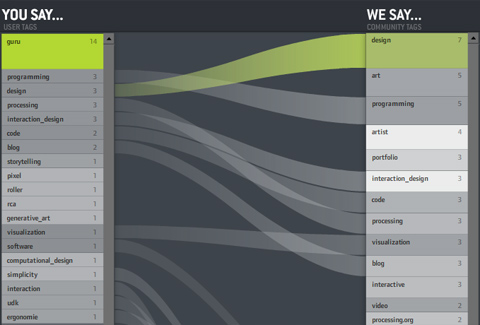
 Recently, Moritz Stefaner at Well-formed Data posted a visualization to compare tagging practices, which could be a useful tool to draw researchers' attention to discrepancies across multiple coders.
Recently, Moritz Stefaner at Well-formed Data posted a visualization to compare tagging practices, which could be a useful tool to draw researchers' attention to discrepancies across multiple coders.A few annotation (aka "code-and-retrieve") packages currently come with embedded intercoder agreement tools. Fewer make much use of visualization tools, generally. My advice to developers is to seriously integrate both functions into the design of next generation CAQDAS software.
1 comment:
Finally, someone trying to push the debate forward by bringing the discussion out of the box. . . thanks, this is great.e
Post a Comment